Previous: Modeling Neurophysiological Data
Up: Modeling Neurophysiological Data
Next: Saturation levels revisited
The data in [De Valois et al. 1966] consist of the averaged responses
of six types of cells in the Macaque LGN to monochromatic stimulus light,
sampled at three radiance levels and 12 to 13 wavelengths for each cell
type. The cell types are designated according to the approximate color of
the light that results in a maximum excitatory (+) or inhibitory ()
response: the four opponent types
,
,
and
, and
the two non-opponent types referred to as excitators and inhibitors, which
I will refer to as
and
, respectively (the symbols are
for
red,
for green,
for yellow,
for blue, and
for any light).
Figure
shows the six data sets.
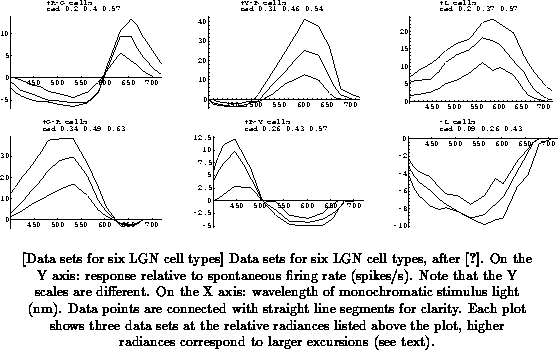
The inhibitory (negative) phases of the responses are generally much
smaller than the excitatory (positive) phases, because they are relative to
the spontaneous firing rate, which is typically 5-10 spikes/s, and negative
firing rates are obviously not possible. The columns of
Figure show pairs of cell types that are complementary in
nature, with responses that are a kind of ``mirror image'' of each other
(when disregarding the absolute sizes of the phases): in a wavelength range
where one type is excited, the other is inhibited (and the other way
around), and the cross-over wavelengths between excitation and inhibition
(if any) are virtually identical. The use of these mirror-imaged channels
is common in the vertebrate visual system, and may be a way to encode a
larger dynamic range than would be possible with a single channel
[Slaughter 1990].
To reconstruct the 3D response functions from this relatively
sparse data set, I started by fitting a model to the data in the radiance
domain, followed by interpolation in the wavelength domain. The reason for
starting in the radiance domain is that a lot is known about the response
characteristics of photoreceptors and other cells in the visual system with
respect to changing stimulus intensity, and this knowledge provides
important constraints on the model. Based on the literature (e.g.,
[Frumkes 1990][Slaughter 1990][Leibovic 1990a]), I have assumed a
sigmoid-shaped function as the basic response model in the radiance domain:
where represents radiance,
the half-response radiance, and
is a
parameter that determines the first derivative around the half-response
point, sometimes referred to as the temperature parameter.
Figure
shows a plot of this function for
and
.
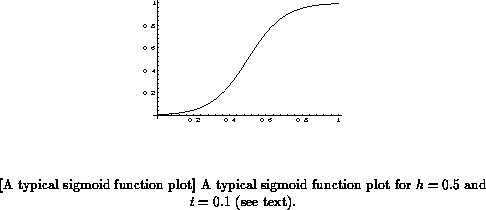
In practice I use a scaled version of the sigmoid function:
where c is a scaling factor that is usually 1, but takes on different values on some occasions (see below).
This type of function is particularly appropriate for modeling, e.g., the
operating curve of photoreceptors that shifts along an absolute radiance
axis as a result of adaptation, as background radiance increases or
decreases [Leibovic 1990a]. The visual system's response is always
relative to its adaptation state, and if we assume a fixed adaptation
state, a function like the one in Figure can be used
to model the response. The parameter
can be interpreted as a function
of the adaptation state. Near
, the sigmoid function is almost linear,
but moving away from
towards
and
it approaches
the limits
and
, respectively. This can be interpreted as
approaching threshold response and saturation response, respectively. The
sigmoid function is also commonly used as a node activation function in
artificial neural networks research (e.g., [Rumelhart et al. 1986]).
To model the response of an LGN cell (type) as a function of radiance (for
a fixed wavelength) with a sigmoid function, we need to interpret the data
points in terms of and
, and then determine appropriate values of
and
that minimize the error of fit. To make the computations
easier, I will use the
interval as the ``useful'' range of
corresponding to a value
going from near-zero (threshold) to
near-one (saturation). The radiances in [De Valois et al. 1966] are
specified as log units below some maximum used radiance. Log
transformations of physical intensity are generally used in psychophysics
to express perceived intensities, since they roughly correspond to a
perceptually linear scale, over a significant part of the useful
range.
Since these
radiances are relative, we need to decide where they should be situated
along the radiance axis. I made the following assumptions:
where is the maximum level used in log units relative to the
background light level,
is the highest and
is the lowest
stimulus radiance used relative to the maximum available,
is
the average firing rate across the spectrum at the highest and
at the lowest radiance used. I used the average responses to
minimize measurement errors. Of course this equation assumes linear
response as a function of log radiance, which we know not to be the case,
but to be approximately true around the half-response radiance. Table
summarizes the results.
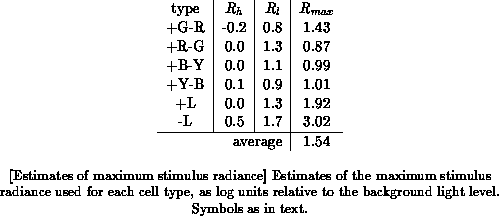
In some cases (viz. +R-G, +B-Y, and especially -L), the estimated maximum
is smaller than the maximum attenuation used, which would imply light
levels below that of the background adaptation light. The article is not
clear on whether or not this was the case, and I have not been able to
determine this any other way. The -L data are all inhibitory, i.e., negative
with respect to the spontaneous firing rate, and thus has a small range.
There may hence be a considerable measurement error involved for this data
set. In any case, it is safe to assume that the total useful range of input
radiances must be at least as large as the average of the values
as given above. In fact it must be at least as large as the maximum value
of
(the maximum attenuation used), viz. 1.7 log units, since the
cells are still responsive at that level. The latter argument would give us
a range of about 2 log units. Since the measurements were most likely done
at radiance levels well below saturation, the total range must be larger
than this, which is consistent with the figure of 3.5 log units mentioned
above.
Although the estimates of the total useful stimulus intensity range and saturation levels are somewhat speculative (since there is not enough data to support better estimates), they are generally not in disagreement with known characteristics of LGN cell responses. In addition, the exact numbers chosen are not all that important, since using different values amounts basically to a linear scaling of the (non-linear) response functions, as I will show below.
With these assumptions in place, we can now fit the sigmoid models to the data. I manually extrapolated the data in the lower and upper wavelength ranges, so each constant-radiance data set starts and ends with a zero point. In addition, I added a zero point to each constant-wavelength set of data points, to constrain the sigmoid fit better. I used the following algorithm to do the fit for each constant-wavelength data set:
1. let data = sign(data)*data
1.1 c = {Abs[NegMax/PosMax], sign < 0
{ 1.0 , otherwise
2. compute least-squares linear fit of data as function of r: a=mr+b
3. let h1 = solution(mr+b=0.5 c) solving for r
4. let t1 = solution(S'(h1,h1,t,c)=m) solving for t
5. minimize(SE2(r,h1,t1,c)) solving for h1 and t1
6. return sign(data)*S(r,h1,t1,c)
Since the sigmoid is really a function of three variables (with
radiance
, half-response radiance
, and temperature
, cf.
equation
p.
), we need to optimize the fit
with respect to one,
, by varying the other two,
and
. The data
form a list of ordered pairs
for a
fixed wavelength and cell type, including the added
point. Step 1 makes sure that all response values are positive. In
principle, a data set may contain both negative and positive response
values, especially around the cross-over point between inhibition and
excitation, although in practice this is rare. This step is more useful for
the inhibitory phases of the response, which are represented as negative
values since I measure responses relative to the spontaneous rate. I
define the sign of the data set as the sign of the sum of the response
values in the set:
where is the data set,
is the function that selects the second
element from an ordered pair,
is the relative radiance, and
is the
response (activation). The sigmoid function has to be either entirely
positive or entirely negative, and this step chooses between those. Note
that this also turns a set of data points whose
's sum to zero into
all-zero
's. This can only happen around the cross-over point between
inhibition and excitation, and is not wrong, even desirable, because
varying the radiance alone should not affect the sign of the response, so
the data are probably unreliable in that case. Step 1.1 chooses the scaling
factor for the sigmoid function, 1 for positive data and the ratio of the
maximum negative to the maximum positive response for negative
data.
To find initial values for
and
,
we first compute a linear fit to the data set in step 2, using
Mathematica's least-squares Fit function. Solving for a linear equation
value of
gives us an initial estimate
for
in step 3 (recall
that
is the half-response radiance, and the sigmoid function values are
normalized to
). Step 4 gives us an estimate
for
such that
the first derivative of the sigmoid function at
is equal to the
slope of the linear equation. This is a reasonable estimate, since the
sigmoid function is near-linear around the half response point, and the
data points cover approximately the first half of the total radiance range.
Step 5 does the actual fit, using Mathematica's FindMinimum function (which
finds local minima using a steepest gradient descent algorithm) on SE2,
which is the summed squared error of fit over the data set. The last step
returns the sigmoid function model for the data set, restoring the sign.
The algorithm works well in practice. Figure
illustrates the procedure, and Figure
shows some
examples of the computed sigmoid fits.

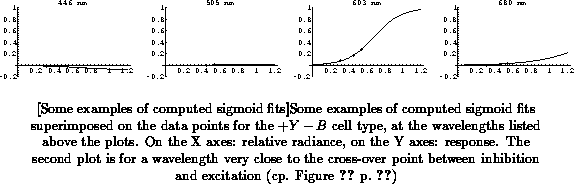
Actually, steps 2 through 4 can be omitted and the minimization started with
initial estimates of for both
and
, but in that case it may
take longer to converge. A constraint
is imposed on the fit;
if it is violated, a different iterative error minimization procedure is
used that keeps
. This constraint serves to prevent slopes of the
sigmoid function that are too steep to serve as realistic models of neural
activation, but in practice this is seldom necessary.
After computing an array of sigmoid fit functions (indexed by wavelength) for each sampled wavelength and each of the six cell types, we can compute the response of each type to an arbitrary wavelength and radiance by interpolating between the values given by the sigmoid functions of radiance that are closest to the given wavelength:
where is the index into the array of sigmoid functions
that we are
looking for,
is the wavelength for which we want to compute a
response, and
is the
-th wavelength for which we have computed
a sigmoid function. Note that before this interpolation is applied, there
is no smoothness constraint imposed on the parameters of the sigmoid fit
from one sampled wavelength to the next, so in principle there could be
serious discontinuities. In practice one would expect the parameters to
change smoothly, and it turns out they do, to a considerable extent at
least. I used Mathematica's standard cubic spline Interpolation function on
the 7 sigmoid function values returned by the series of functions centered
around
, adding additional zero points above and below the sampled
wavelength range (and specifying 0 first and second derivatives for the
very lowest and highest, to constrain the interpolation better):
where is the computed response (activation),
computes a cubic spline interpolation function for the points in list
and evaluates it at
,
is the
-th radiance level and
the corresponding sigmoid function we have previously computed, and
is the relative radiance and
the wavelength for which we want
to compute the response. The resulting functions are shown in
Figure
for the same relative radiances as in
Figure
(p.
), and additionally for
maximum relative radiance
.
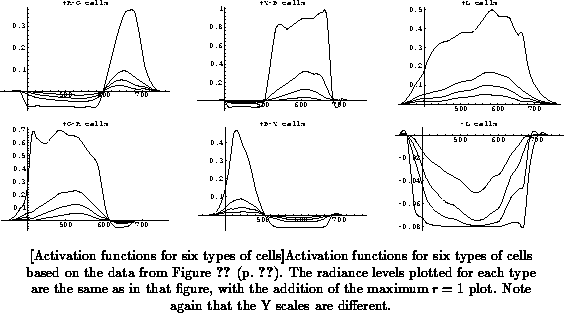
We can see that the functions follow the data sets closely at the sampled
wavelengths and radiances, but they are continuous and extend beyond the
sampled data in both domains. We can see some irregularities in the maximum
radiance level responses, which results from extrapolating the data
considerably, combined with the absence of smoothness constraints as
explained above. These irregularities will largely disappear in the next
processing step, as explained in Section
(p.
). It is interesting to note the clear saturation
effect in most inhibitory response phases, and in the excitatory phases of
the
and
functions, due to the use of the sigmoid model. If we
continued to compute function values at ever higher radiances, saturation
would eventually also set in in the other functions. It is not clear
whether the radiance range should be extended further to allow all
functions to reach saturation levels. Alternatively, the radiance axis
could be normalized for each function individually, or perhaps for opponent
pairs of functions, but that is not in agreement with the assumptions I
outlined above. Saturation effects are clearly in agreement with
neurophysiological data, but to my knowledge there is no other color model
available that incorporates them.